
MADRID, 10 (Portaltic/EP)
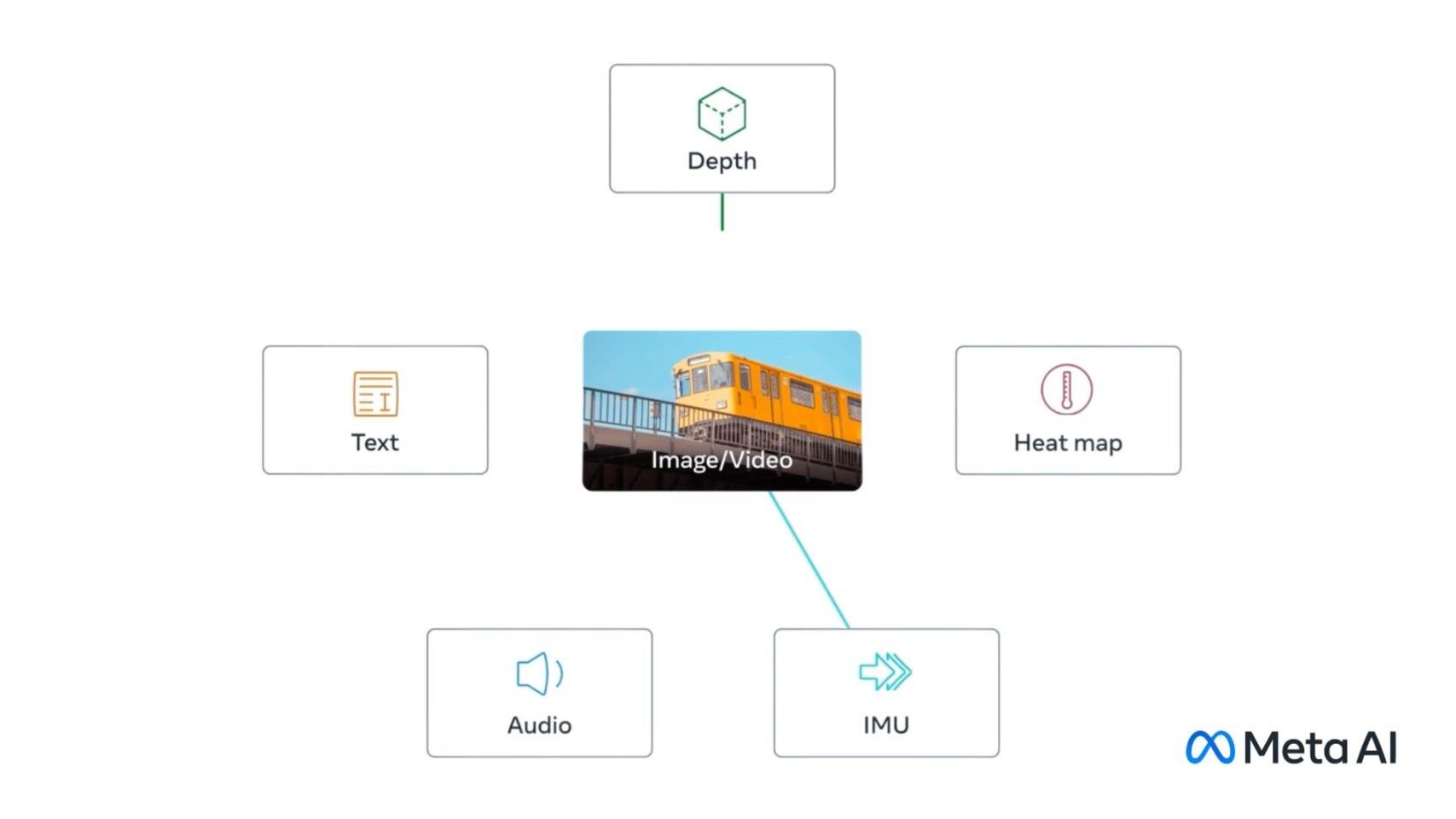
La compañía ha comentado que ImageBind, un proyecto que forma parte de la iniciativa de crear sistemas multimodales capaces de aprender de diferentes tipos de datos, puede vincular seis tipos de fuentes de entrada.
De hecho, este modelo aprende un espacio de representación integrado en el que convergen diversos elementos- texto, imágenes, vídeos y audio- y registra factores, como la profundidad (3D) y la temperatura, de distintos sensores, y las unidades de medición inercial, que calculan el movimiento y la posición,
Asimismo, Meta ha insistido en que ImageBind "también podría proporcionar una forma rica de explorar los recuerdos: búsqueda de fotos, vídeos, archivos de audio o mensajes de texto mediante una combinación de texto, audio e imagen".
Esto es posible porque, al contrario que los sistemas habituales de IA, que estudian vectores de forma individual y según la modalidad de estos datos, la herramienta de Meta "crea un espacio de incrustación conjunto para múltiples modalidades" sin que sea necesario entrenarlo con datos de cada combinación de estas fuentes (esto es, solo vídeo o solo audio, por ejemplo).
La compañía tecnológica cree que este factor es lo que le diferencia de otras IA, ya que su herramienta intenta aprender de un único espacio de características "para múltiples modalidades" o contextos; unas capacidades que irá mejorando conforme vaya aprovechando las características visuales de DINOv2.
Esta solución, por otro lado, puede interpretar el contenido de forma más holística, permitiendo que las distintas modalidades se comuniquen entre sí y encuentren vínculos sin necesidad de analizarlas a la vez. Esto es, puede establecer correlaciones naturales entre audio y texto sin aprenderlos a la vez.
Gracias a eso, otros modelos de aprendizaje pueden comprender nuevas modalidades de ImageBind sin necesidad de un aprendizaje que consuma muchos recursos gracias a su fuerte comportamiento de escalado.
Finalmente, Meta ha sugerido que, aunque en su investigación actual ha explorado seis modalidades, cree que la introducción de nuevas variantes -como el tacto, el habla o el olfato- permitirá crear modelos de IA centrados en el ser humano.


